Duże modele językowe zostały wytrenowane przy użyciu ogromnych ilości danych tekstowych. Zostały one przeszkolone do przewidywania następnego słowa na podstawie danych wejściowych. Stwierdzono, że jeżeli model jest wystarczająco duży, może nauczyć się nie tylko gramatyki ludzkich języków, ale także znaczenia słów, wiedzy potocznej czy nawet prymitywnej logiki.
Mając na uwadze powyższe, jeżeli podamy modelowi fragmentaryczne zdanie: "Pies mojego sąsiada jest... (jako dane wejściowe, tj. komenda), może on przewidzieć "inteligentny" lub "mały" ale raczej nie "sekwencyjny", chociaż każde z nich jest przymiotnikiem. Podobnie, jeżeli dostarczymy do modelu pełne zdanie, możemy spodziewać się zdania, które naturalnie wynika z danych wyjściowych modelu. Wielokrotne dołączanie danych wyjściowych modelu do oryginalnych danych wejściowych i ponownie wywoływanie modelu może sprawić, że model wygeneruje długą odpowiedź.
Zero-Shot Prompting
W modelach przetwarzania języka naturalnego, podpowiedź zero-shot oznacza dostarczenie podpowiedzi, która nie jest częścią danych treningowych do modelu, ale model może wygenerować pożądany wynik. Ta technika sprawia, że duże modele językowe są przydatne w wielu zadaniach.
Czemu takie podejście jest przydatne? Spójrzmy na analizę sentymentu (do czegoś): w ramach testu możemy wziąć akapity z różnymi opiniami i oznaczyć je klasyfikacją sentymentu. Następnie możemy wytrenować model uczenia maszynowego (np. RNN na danych tekstowych), aby przyjmował akapit jako dane wejściowe i generował klasyfikację jako dane wyjściowe. Okazuje się jednak, że taki model nie jest adaptacyjny. Jeżeli dodamy nową klasę do klasyfikacji lub poprosimy, aby model nie klasyfikował akapitów, ale je podsumowywał, model ten musi zostać zmodyfikowany i ponownie przeszkolony.
Duży model językowy nie musi być jednak ponownie trenowany. Możemy poprosić model o sklasyfikowanie akapitu lub podsumowanie go, jeżeli wiemy, jak poprawnie go o to zapytać. Oznacza to, że model prawdopodobnie nie może zaklasyfikować akapitu do kategorii A lub B, ponieważ znaczenie "A" i "B" jest niejasne. Mimo to, może sklasyfikować go jako "pozytywny sentyment" lub "negatywny sentyment", ponieważ model wie, co powinno być "pozytywne" i "negatywne". Takie podejście działa, ponieważ podczas szkolenia model nauczył się znaczenia tych słów i nabył umiejętności wykonywania prostych instrukcji.
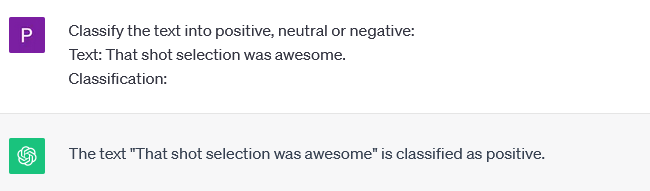
Spójrzcie na przykład w oparciu o ChatGPT-3.5:
Dostaliśmy co prawda odpowiedź pełnym zdaniem ale zgodnie z naszą klasyfikacją otrzymaliśmy słowo positive - poprawna i zwięzła klasyfikacja. Model, którego używamy potrafi zrozumieć znaczenie słowa "niesamowity", wie, że jest to pozytywne doznanie ale sama umiejętność zidentyfikowania tego doznania wynika z początkowej instrukcji, tj.; "Sklasyfikuj tekst jako pozytywny, neutralny lub negatywny."
Na bazie tego przykładu możemy stwierdzić, że model zareagował, ponieważ zrozumiał instrukcje.
Few-Shot Prompting
Jeżeli nie możemy opisać tego, czego chcemy, ale wciąż chcemy, aby model językowy udzielił nam odpowiedzi, możemy podać kilka przykładów. To zawiłe zdanie łatwiej wyjaśnić na poniższym przykładzie:
Jak widzicie nie podaliśmy żadnej instrukcji co należy zrobić, ale dzięki kilku przykładom model może dowiedzieć się jak zareagować. Ciekawi mnie jedynie czemu model zwrócił odpowiedź "negative" zamiast "Neg" podanego w przykładzie.
Po angielsku się udało. Spróbujmy odtworzyć podobną sytuację, ale w języku polskim. Ponownie wykorzystamy technikę few-shot prompting w której przekażemy do modelu niewielką liczbę przykładów (zwykle od 2 do 5) w celu szybkiego nauczenia modelu jak ma wykonać zadanie, do którego nie był wcześniej trenowany. Tak jak wspomniałem wcześniej, do duże ułatwienie w stosunku do tradycyjnego uczenia maszynowego, gdzie model musi być ćwiczony na dużych zestawach danych, aby osiągnąć wysoką skuteczność. Spójrzmy na poniższy przykład napisany w języku polskim:
Samochód: rodzaj pojazdu silnikowego, służący do przewozu osób lub ładunków.
Rower: jedno-lub wielośladowy pojazd kołowy napędzany siłą mięśni poruszających się nim osób za pomocą przekładni mechanicznej, wprawianej w ruch (najczęściej) nogami.
Pociag: zestaw wagonów z lokomotywą lub wagonem silnikowym, poruszający się po szynach po wyznaczonej trasie.
Prom kosmiczny:
Oraz odpowiedź:
Tym razem też się udało. Wystarczyło tylko kilka zdań, aby model nauczył się wzorca. Przy bardziej skomplikowanych zadaniach pewnie trzeba będzie poeksperymentować z większą liczbą przykładów, żeby uzyskać pożądany efekt – dla nas najważniejsze było jednak nauczenie się podstaw tej techniki.
Muszę również przyznać, że jestem zaskoczony odpowiedziami w języku polskim. Z założenia ta seria wpisów miała być przygotowana z wykorzystaniem poleceń pisanych w języku angielskim, ale widzę, że nic nie stoi na przeszkodzie, żeby przełączać się pomiędzy językami. Kolejny wpis, w którym spróbujemy zrobić burzę mózgów przeprowadzimy w języku polskim, wiadomość e-mail do naszego klienta przygotujemy po angielsku a kolejne wpisy będziemy dopasowywać na bieżąco do naszych potrzeb.

 Dostaliśmy co prawda odpowiedź pełnym zdaniem ale zgodnie z naszą klasyfikacją otrzymaliśmy słowo
Dostaliśmy co prawda odpowiedź pełnym zdaniem ale zgodnie z naszą klasyfikacją otrzymaliśmy słowo 
